.jpg)

图的存储
稠密图用邻接矩阵
稀疏图用邻接表
深度优先遍历O(n+e)
什么是深度优先遍历?
类似树的先根遍历,从顶点v0出发,访问它一个不曾被访问过的邻接顶点v1,再从v1出发,访问v1一个不曾访被访问过的顶点v2,如此往复,直至达到一个顶点,他不再有未访问的邻接顶点。然后回溯到上一个被访问的顶点,查看是否有未被访问的邻接顶点,若有,则按照前述方式进行访问。
图如下
graph = {
1: [2, 7],
2: [3],
3: [4, 5],
4: [5],
5: [6],
6: [1],
7: [6],
}深度优先遍历递归算法如下:
数据机构:邻接表+visited数组
def DFS_Main(Head):
"""如果图是非连通图,就需要多次调用DepthFirstSearch,才能访问到所有顶点"""
visited = [None] * (len(Head)+1)
for i in range(1, len(Head)):
if visited[i] is None:
DepthFirstSearch(Head, i, visited)
def DepthFirstSearch(Head, v, visited):
"""
图的深度优先遍历
:param Head: 邻接表存储的图
:param v: 开始遍历的顶点
:param visited: 表示标志顶点是否被访问的数组,被访问则设定为1
:return:
"""
print(v)
visited[v] = 1
p = Head[v]
for i in range(len(p)):
if visited[p[i]] != 1:
DepthFirstSearch(Head, p[i], visited)注:时间复杂度O(n+e),,n为顶点数,e为边数
深度优先遍历迭代算法思路:
将所有visited数组值置为0,初始顶点v0入栈
检测堆栈是否为空,若堆栈为空,则迭代结束
从栈顶弹出一个元素v,如果v未被访问过(visited[v]=0),则
访问v,并将visited[v]更新为1
将v的未被访问的临接结点入栈
执行步骤2
深度优先遍历迭代算法如下:
数据结构:邻接表+stack+visited数组
def DFS(graph, param, visited):
"""
深度遍历迭代函数,每次出栈将其一个邻接点入栈
:param graph: 邻接图
:param param: 遍历的起始顶点
:param visited: 辅助数组是否被访问
:return:
"""
stack = []
stack.append(param)
while stack:
p = stack.pop()
if visited[p] != 1:
print(p, end=' ')
visited[p] = 1
v = graph[p]
count = len(v)
for i in range(count):
if visited[v[i]] != 1:
stack.append(v[i])注:时间复杂度O(n+e),,n为顶点数,e为边数
广度优先遍历O(n+e)
什么是广度优先遍历?
类似树的层次遍历,先访问初始顶点v0,之后依次访问与v0邻接的全部顶点w1,w2...然后再顺次访问与w1,w2...邻接的尚未访问的全部顶点,再从这些被访问过的顶点出发,逐个访问与他们邻接的尚未访问过的全部顶点,重复这个过程,直至所有顶点全部访问为止。
算法基本思路:
将所有顶点的visited值置为0,访问初始顶点v0,设置visited[0]=1,v0入队
检测队列是否为空,若队列非空,则迭代结束
从队头取出一个顶点v,检测其每个邻接顶点w:
如果w没被访问过
访问w
将visited[w]值更新为1
将w入队
重复执行步骤2
代码实现如下:
def BFS(graph, param, visited):
"""
广度遍历迭代函数,每次出队将其邻接点都入队
:param graph: 邻接图
:param param: 遍历的起始顶点
:param visited: 辅助数组是否被访问
:return:
"""
queue = Queue()
queue.put(param)
while not queue.empty():
p = queue.get()
if visited[p] == 0:
print(p, end=' ')
visited[p] = 1
v = graph[p]
count = len(v)
for i in range(count):
if visited[v[i]] != 1:
queue.put(v[i]) 注:该算法时间复杂度为O(n+e)
拓扑排序
什么是拓扑排序?
存在图G=(V,E),AVO网上所有节点成线性序列,且该序列满足:若存在边<vi,vj>,则在该排序中,vi必位于vj之前发生,称为拓扑排序。
注:存在回路的图,就无法找到其拓扑排序
算法基本思想:
从网中选择一个入度为0的顶点且输出
从网中删除该顶点及其所有边
执行1、2直至所有顶点已输出,或网中剩余顶点入度不为0(说明网中存在回路,无法继续拓扑排序)
注:拓扑排序算法可以判断一个图是否存在回路
图如下:
graph_topo = {
0: [1, 2, 3],
1: [],
2: [1, 4],
3: [4],
4: [],
}拓扑排序算法如下:
def TopoOrder(graph, n):
"""
该函数使用top指针模拟栈,节省空间
初始化:
top = -1
入栈操作(count[i]记录次栈顶元素):
count[i] = top
top = i
出栈操作(top退回到次栈顶):
j = top
top = count[j]
:param graph:
:param n:
:return:
"""
"""初始化count数组"""
top = -1
count = [0] * (n+1)
"""计算各个点的入度,遍历邻接表,被访问到就+1,下标对应图中的顶点"""
for i in range(n):
v = graph[i]
for j in range(len(v)):
count[v[j]] += 1
"""入度为0的点进栈"""
for i in range(n):
if count[i] == 0:
count[i] = top
top = i
"""
进行拓扑排序,n个点循环n次,取出栈顶元素,访问该点
遍历该点的邻接表元素,并将其对应的count数组中的数值-1模拟删除该点
如果该点的入度为0,也就是count数组内的数字为0,则入栈
"""
for i in range(n):
if top == -1:
print('图内存在环')
return
else:
j = top
top = count[top] # 出栈
print(j, end=' ')
p = graph[j]
for t in range(len(p)):
count[p[t]] -= 1
if count[p[t]] == 0:
count[p[t]] = top
top = p[t] # 入栈注:时间复杂度O(n+e),n为顶点数,e为边数
关键路径(会自己推)
ve:各个事件最早的发生时间(顺着推,max)
vl:各个顶点事件的最迟发生时间(逆着推,min)
e(i):各个活动最早开始时间(顺着推,看活动发出端)
l(i):各个活动最迟开始时间(逆着推,看活动的结束段)
l(i)-e(i)=0,则为关键路径
什么是关键路径?
在AOE网中有些活动可以并行进行,因此完成整个工程的最短时间是从源点到汇点的最长路径(路径长度等于路径上各边的权之和,而不是路径上弧的数目),这条拥有最大长度的路径称为关键路径。
拓扑排序后的图如下:
graph_critical = {
1: [(2, 6), (3, 4), (4, 5)],
2: [(5, 1)],
3: [(5, 1), (6, 1)],
4: [(6, 2)],
5: [(7, 9), (8, 8)],
6: [(8, 4)],
7: [(9, 2)],
8: [(9, 4)],
9: [],
}算法实现如下:
需要创建ve、vl数组
def CriticalPath(Head):
"""
寻找拓扑排序中的关键路径,假设入参已经进行拓扑排序
:param Head: 邻接表
:return:
"""
"""ve:各个事件最早的发生时间"""
ve = [0] * (len(Head) + 1)
ve[0] = None # 更好查看
"""计算ve"""
for i in range(1, len(Head)):
p = Head[i]
for j in range(len(p)):
if ve[p[j][0]] < p[j][1] + ve[i]:
ve[p[j][0]] = p[j][1] + ve[i]
print('ve:', ve)
"""le:各个事件最迟的发生时间"""
vl = [ve[-1]] * (len(Head) + 1)
vl[0] = None
for i in range(len(Head), 0, -1):
p = Head[i]
for j in range(len(p)):
if vl[p[j][0]] - p[j][1] < vl[i]:
vl[i] = vl[p[j][0]] - p[j][1]
print('vl:', vl)
for i in range(1, len(Head)):
p = Head[i]
for j in range(len(p)):
"""i是活动起始点,k是活动终止点"""
k = p[j][0]
e = ve[i]
l = vl[k] - p[j][1]
if l == e:
print('<'+str(i)+','+str(k)+'> is Critical Activity!')最短路径
无权最短路径问题
类似广度遍历算法,第一次广度遍历查询到的点距离为1,第二次为2...以此类推
数据结构:邻接表+队列
需要创建dist、path数组
算法如下:
def ShortestPath(Head, v, n):
"""
寻找初始顶点
pish[i] 记录v到i的最短路径上的顶点i的前驱结点
dist[i] 记录从v到i的最短路径长度
"""
path = [-1] * n
dist = [-1] * n
dist[v] = 0
queue = Queue()
queue.put(v)
"""
访问出栈结点的邻接点
如果dist值为-1说明未被访问
将邻接结点的dist值更新为出栈值+1
邻接结点的path值更新为出栈结点
邻接结点入栈
"""
while not queue.empty():
u = queue.get()
p = Head[u]
for i in range(len(p)):
k = p[i]
if dist[k] == -1:
queue.put(k)
dist[k] = dist[u]+1
path[k] = u
print("dist:", dist)
print("path:", path)注:时间复杂度O(n+e)
正权最短路径问题---Dijkstra算法
数据结构:邻接表+三个数组
visited[i] 辅助数组,标记是非被访问过
dist[i] 记录从v到i的最短路径长度
pish[i] 记录v到i的最短路径上的顶点i的前驱结点算法思路:
设S为初始顶点,dist[s]=0且除了s,其他dist数组内的值置为正无穷
在未被访问的结点中选择dist中最小的值v访问,令visited[v]=1
依次考察v的邻接顶点w,若Dv+weight(<v,u>)<Dw,则更新Dw的值,使Dw=Dv+weight(<v,u>)
重复执行2、3直至所有顶点皆被访问
算法过程如下:
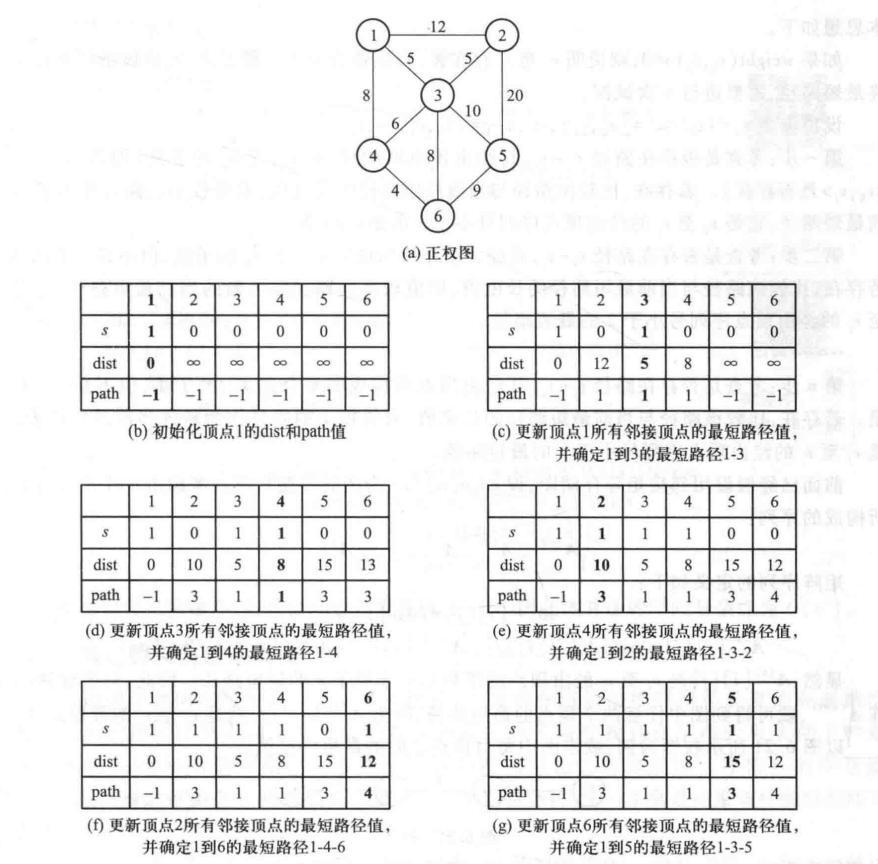
算法实现如下:
def Dijkstra(Head, v, n):
"""
dist[i] 记录从v到i的最短路径长度
pish[i] 记录v到i的最短路径上的顶点i的前驱结点
"""
visited = [0] * (n+1)
path = [-1] * (n+1)
dist = [float('inf')] * (n+1)
dist[v] = 0
visited[v] = 1
p = Head[v]
u = v
for i in range(1, n-1):
"""更新dist、path数组"""
for j in range(len(p)):
"""Du+weight<Dw"""
if visited[p[j][0]] != 1 and dist[u] + p[j][1] < dist[p[j][0]]:
dist[p[j][0]] = dist[u] + p[j][1]
path[p[j][0]] = u
ldist = float('inf')
for k in range(1, n):
if dist[k] < ldist and visited[k] == 0:
ldist = dist[k]
u = k
visited[u] = 1
p = Head[u]
print("dist:", dist)
print("path:", path)注:算法时间复杂度为O(n^2)
每对顶点之间的最短路径---Floyd
数据结构:邻接矩阵+Path矩阵
算法思路:
已知初始邻接矩阵A-1,更新矩阵,新矩阵记为A0,记为将0作为中间点,各个点能达到的点
以此类推,不断更新矩阵,直至计算到A(n-1)
算法实现如下:
path保存该结点由i到j路径的前驱
入参:邻接矩阵,节点个数,Path矩阵
返回:邻接矩阵,Path矩阵
注意要点:
每次变换对角线以及中间点的行和列的值不变
更新条件之一:增加以k为中间点的路径小于原路径,则将邻接矩阵中的值更新为更短的路径,对应的path_ij保存path_kj的值
def Folyd(A, n, path):
"""
Folyd假设矩阵初始化完成且path矩阵初始化完成
path保存该结点由i到j路径的前驱
"""
for k in range(n-1):
"""遍历每个元素"""
for i in range(len(A)):
for j in range(len(A)):
if (i != j and k != i and k != j # 对角线不改变,k行k列不变
and A[i][k] < float('inf')
and A[k][j] < float('inf') # i到k可达,k到j可达
and A[i][j] > A[i][k] + A[k][j]):
# 原路径大于以k为中间点的路径,则更新路径,Path[i][j]更新为path[k][j]
A[i][j] = A[i][k] + A[k][j]
path[i][j] = path[k][j]
print(A)注:该算法包含三重循环,复杂性为O(n^3)
满足约束的最短路径
最小支撑树
什么是最小支撑树?
从图G = {V,E, C}中选出n-1条边
以n-1条边将图的n个顶点构成一个连通图
该连通图是满足条件1且具有最小权值的连通图
这样的连通图被称为网络N的最小支撑树。
最小支撑树不止一条
Prim算法---求稠密网络的最小值支撑树
先选定边在选择点
数据结构:邻接矩阵+closedge和TE数组
closedge数组:
算法思路:
存在一个V的非空子集U,初始放入一个点
找到除U中结点外的其他到U集合中的最短的结点路径
不断更新U,增加新节点,直至U=V
算法过程如下:
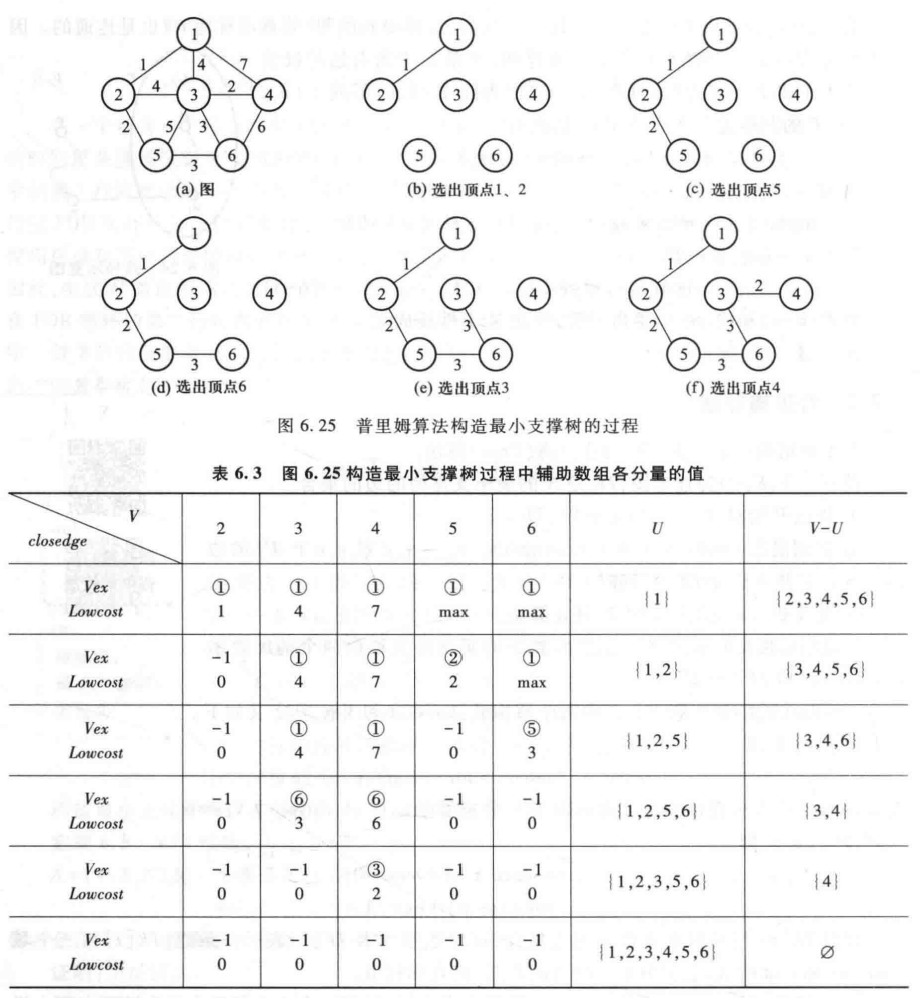
算法实现如下:
closedge[n]:每个数组元素由Lowcost和Vex两个值域构成
Lowcost保存V-U中的结点到U中最短路径长途
Vex存储的是依附在U中的顶点
被纳入U中的结点Lowcost为0,Vex为-1
TE[n-1]:保存最小支撑树的路径,每个数组元素由head、tail、cost构成
head:路径的起始点
tail:路径的结束点
cost:路径的权值
入参:邻接矩阵,节点个数
返回:TE
注意要点:
每次循环选出一个距U集合最短的路径的点
每次U集中加入新节点需要更新closeage数组的值
更新除U集外结点[closedge[t].Vex != -1]
邻接矩阵中存在到新加入U集的结点最近的路径更新[graph_v(新加入U集结点)_t < closedge[t].Lowcost]
closedge[t].Lowcost = graph[v][t]
closedge[t].Vex = v
graph_Prim = [[-1, -1, -1, -1, -1, -1, -1],
[-1, 0, 1, 4, 7, float('inf'), float('inf')],
[-1, 1, 0, 4, float('inf'), 2, float('inf')],
[-1, 4, 4, 0, 2, 5, 3],
[-1, 7, float('inf'), 2, 0, float('inf'), 6],
[-1, float('inf'), 2, 5, float('inf'), 0, 3],
[-1, float('inf'), float('inf'), 3, 6, 3, 0]]def Prim(graph, n):
"""
最小支撑树Prim算法:求稠密网络的最小支撑树
closedge[n]:每个数组元素由Lowcost和Vex构成
Lowcost:集合内点到V中各个点的最小边长
Vex:该边依附在U中的顶点
v属于U,则Lowcost = 0;Vex = -1
TE[n-1]使最小支撑树的的边集合
TE[i]表示一条边,TE[i]由三个域head,tail,cost构成
"""
closedge = [None] * (n+1)
TE = [None] * (n-1)
"""初始化closedge,Vex都设为1"""
for i in range(1, n+1):
closedge_Node = Closedge_Node(graph[1][i], 1)
closedge[i] = closedge_Node
closedge[1].Vex = -1
count = 0
for i in range(2, n+1):
for k in range(1, n+1):
print(closedge[k].Lowcost, closedge[k].Vex, end='||')
print('')
v = 0
min_cost = math.inf
for j in range(1, n+1):
if closedge[j].Vex != -1 and closedge[j].Lowcost < min_cost:
v = j
min_cost = closedge[j].Lowcost
if v != 0:
"""
v = 0 说明没有找到符合条件的顶点
向支撑树TE中加一条边
"""
head = closedge[v].Vex
tail = v
cost = closedge[v].Lowcost
node = TE_Node(head, cost, tail)
TE[count] = node
count += 1
closedge[v].Lowcost = 0
closedge[v].Vex = -1
"""更新closedge相关信息"""
for t in range(1, n+1):
if closedge[t].Vex != -1 and graph[v][t] < closedge[t].Lowcost:
closedge[t].Lowcost = graph[v][t]
closedge[t].Vex = v
for i in range(0, len(TE)):
print('TE:', TE[i].head, TE[i].tail, TE[i].cost)注:时间复杂性O(n^2)
Kruskal算法---求稀疏网络的最小支撑树
先选定所有点再选边
数据结构:邻接矩阵+Make_set和rank数组
算法思路:
图G={V,E,C},T为最小支撑树,初始时T={V},只有顶点没有边,n个连通分量
在E中选择权值最小的边,并将此边删除
如果此边的两个顶点在T的不同连通分量中,则将此边加入T,从而导致T中减少一个连通分量,因为多了一条边,将两个连通分量变为一个
重复执行以上步骤,直至T中连通分量为1
算法过程:
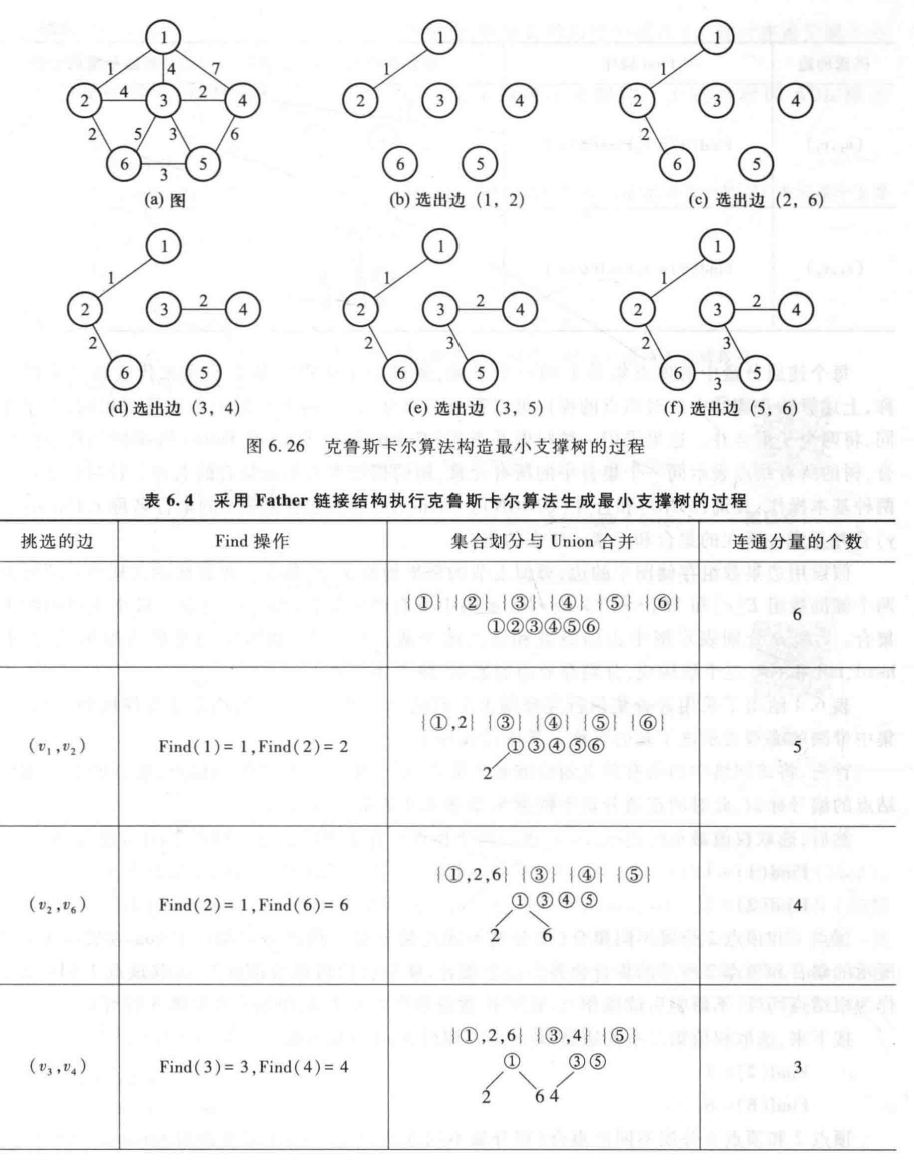
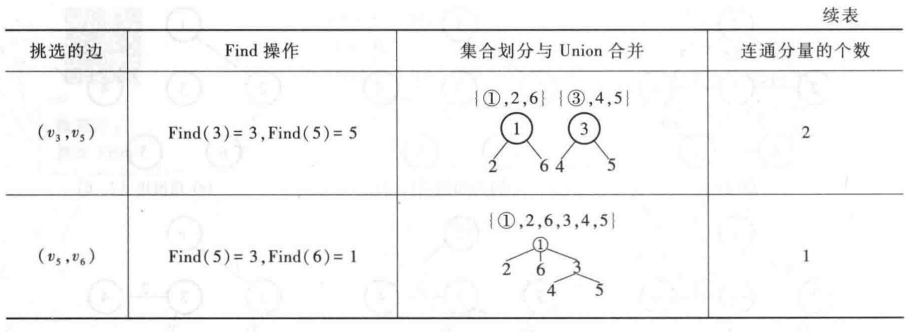
算法实现如下:
Make_set[n]:表示每个顶点所在的连通分量,Make_set[i]=k表示顶点i和k在一个连通分量中。
rank[n]: 表示为每个顶点的秩。
入参:按照cost排序完成的边集合,顶点个数
返回:TE
注意要点:
算法采用并查集来实现连通分量的合并
E = [(1,2,1), (2,6,2),
(3,4,2), (3,5,3),
(5,6,3), (1,3,4),
(2,3,4), (3,6,5),
(4,5,6), (1,4,7)]def Kruskal(E, n):
"""
Kruskal算法最小生成树:稀疏网络的最小支撑树
:param E: 边的集合
:param n: 顶点个数
:return:
"""
"""
Make_set[n]:表示每个顶点所在的连通分量,Make_set[i]=k表示顶点i和顶点k在一个连通分量内
rank[n]:表示每个顶点的秩
"""
Make_set = [None] * (n+1)
rank = [None] * (n+1)
for i in range(1, n+1):
Make_set[i] = i
rank[i] = 0
T = n
TE = [None] * (n-1)
j = 0
count = 0
while T > 1:
Vex_1 = E[j][0]
Vex_2 = E[j][1]
cost = E[j][2]
if Find(Make_set, Vex_1) != Find(Make_set, Vex_2):
TE[count] = TE_Node(Vex_1, cost, Vex_2)
count += 1
Union(Make_set, rank, Vex_1, Vex_2)
T = T-1
j += 1
for i in range(len(TE)):
print(TE[i].head, TE[i].tail, TE[i].cost, end='//')
def Find(Make_set, z):
r = z
while r != Make_set[r]:
r = Make_set[r]
"""路径压缩:压缩查询路径,将从结点z到根节点的路径上的所有结点都作为根节点的儿子结点"""
k = z
while k != r:
j = Make_set[k]
Make_set[k] = r
k = j
return r
def Union(Make_set, rank, x,y):
f_1 = Find(Make_set, x)
f_2 = Find(Make_set, y)
if rank[f_1] <= rank[f_2]:
Make_set[f_1] = f_2
if rank[f_1] == rank[f_2]:
rank[f_2] += 1
else:
Make_set[f_2] = f_1注:时间复杂度为O(eloge)
.jpg)
.jpg)